Stirling: Run Llama, DeepSeek & Qwen Locally – The Dev’s Dream Editor
#AI #EarnCrypto #stirling
Stirling (featured on Quasa.io/projects/stirling) is a powerful, open-source AI code editor that's quickly becoming a favorite alternative to Cursor, Windsurf, or VS Code + Copilot in 2026.
Built on top of Ollama/local LLMs (or cloud models), it offers lightning-fast autocomplete, full-file editing, chat sidebar, inline code explanations, refactoring suggestions, and even autonomous agent-like behavior for complex tasks—all while keeping your code private and running locally if desired.
Key strengths: extremely low latency (feels instant even on mid-range hardware), beautiful dark/light themes, excellent multi-file awareness, support for huge context windows (up to 128k+ tokens on good models), built-in terminal integration, Git support, and a clean, distraction-free UI.
You can switch between models (Llama 3.1, DeepSeek-Coder-V2, Qwen 2.5-Coder, etc.) with one click, and the community is actively adding extensions/plugins.
It's completely free (no subscription trap), actively developed, and already outpacing many paid tools in speed and privacy for solo devs, indie hackers, and anyone tired of cloud-dependent IDEs. Minor cons: still maturing ecosystem compared to VS Code, occasional model-specific quirks, and setup takes ~5 minutes the first time.
A must-try for developers who want fast, private, powerful AI coding assistance without paying monthly fees — earn 1 QUA reward via Quasa too!
4.8/5 stars (outstanding speed, privacy, and value; slight dock for smaller extension marketplace and occasional UI polish needed).
Get started: https://quasa.io/projects/stirling
In case you missed it

Compose AI Review: Smart Autocomplete for Everyday Writing

Guidde Review: AI Video Documentation Made Magical

DataRobot Review: Unified Agent Workforce Platform for Enterprise

8090 Review: AI-Native Software Factory for Regulated Enterprises

Rocket Lab Review: End-to-End Space Company Driving Innovation

AIPRM Review: The Ultimate Prompt Library & Manager for ChatGPT & AI

95% of “Blockchains” Are Not Blockchains – They’re Centralized Databases in Disguise

Corgi Insurance Review: Instant Quotes & Startup-Focused Coverage
Papermark Review: Modern Secure Data Rooms for Dealmakers

The Crypto Gold Rush Is Over: 2025–2026 Became the Biggest Graveyard in Financial History

General Intuition Review: Building World Models from Gameplay Data

The Great Crypto Reckoning: Why 96% of Projects Will Die by 2027

Monday Review: The AI Work Platform for People & Agents

Maestro Labs Review: AI Assistants for Email & Meetings

Friday AI Email Review: Reclaim Your Inbox and Save Hours

The Death of Traditional Freelancing in 2026: AI + Web3 Report

The Final Bloodbath: Insiders Dumping & Dead Cat Bounce

Superhuman Review: The Ultimate AI Productivity Suite for Professionals

Bricks AI Review: Sales Enablement for On-Brand Personalized Documents

Synthflow AI Review: Enterprise Voice Agents for Phone Automation

Spinach AI 2026 Review: The Intelligent Meeting Assistant for Productive Teams

90% of Crypto Projects Have Billion-Dollar Market Caps but Almost Zero Traffic and Revenue

Nebius Review: The Ultimate AI-Native Cloud for Builders.

Maven AGI Review: Enterprise AI Agents for Superior Customer Experience.

Sudowrite 2026 Review: The Best AI Writing Partner for Fiction Authors

Tenable 2026 Review: Leading AI-Powered Exposure Management Platform

10 CEX That Killed More Projects Than All Hackers Combined

AssemblyAI Review: The Leading Voice AI Infrastructure Platform

Black Crow AI 2026 Review: Predictive AI for Full-Funnel Ecommerce Growth

The Crypto Market Is Dead: 6,000 Out of 8,000 Projects Are Scams

Vibiz Review: No-Code AI That Builds & Launches Your Business

Bloomreach Review: Loomi AI Powers Next-Level Personalized Commerce

Lavender Review: The AI Email Coach That Doubles Reply Rates

The Disgusting Six: Crypto’s Most Damaging Players vs One Honest Project

CodeSignal Review: The AI-Native Skills Platform for Modern Hiring

Anyword: The Performance-Driven AI Content Platform for Marketers

Gong Review: The Revenue AI OS Driving Predictable Growth

Persado Review: AI for Compliant, High-Performing Marketing Content

HubSpot Review: The All-in-One AI Customer Platform

Jimdo 2026 Review: Easy AI Website Builder for Solopreneurs & Small Business

CoLoop Review: The AI Copilot for Qualitative Research & Insights

Ideanote Review: The AI-Native Platform for Innovation Management

Visla Review: The All-in-One AI Video Platform for Business Teams

The Great Exit Has Begun: Insiders, VCs, Governments & Even Saylor’s Company Are Dumping Bitcoin.

CrewAI Review: The Leading Platform for Multi-Agent AI Systems

Wand AI Review: The Operating System for Hybrid Human-AI Workforces

Tonkean Review: The Leading Agentic Orchestration Platform for Enterprises

Chroma Review: The Best Open-Source Vector Database for AI Search

Dreamina AI 2026 Review: ByteDance’s All-in-One AI Image & Video Generator

LangChain Review: The Ultimate Framework for Building AI Agents

Langfuse Review: The Best Open-Source LLM Observability Platform

Gradio: The Easiest Way to Build & Share AI Web Apps

VEED Review: The Best All-in-One AI Video Editor for Creators

Snowflake AI Data Cloud Review: The Foundation for Enterprise AI

Durable AI Review: Build Your Entire Business Website in 30 Seconds

Quilty Review: AI Script Coverage That Actually Helps Writers & Producers

Pictory AI Review: The Best Text-to-Video Tool for Creators & Marketers

Thinking Machines Lab: The Future of Human-AI Collaboration

Hugging Face Review: Open Models, Datasets & AI Apps

QuillBot: The Best AI Paraphrasing & Writing Tool

Fotor: AI Photo Editor & Image Generator.

The State of the Cryptocurrency Industry in 2026: An Industry Built on Illusion

Presentations AI 2026: AI Decks That Actually Drive Results

Beautiful AI: AI That Creates Beautiful Presentations

XGRIDS Review: Handheld LiDAR & Photorealistic Digital Twins

Arize AI: Observability & Evaluation for AI Agents

Formula Bot Review: Turn Questions into Charts & Insights Instantly

Quasa Connect: The World’s First Web3 Freelance App

Rows Review: The Modern AI Spreadsheet Platform

Tettra Review: The Best Internal Knowledge Base for Slack Teams

Taskade: The Beautiful AI-Powered Workspace

Gigasheet: Big Data Analysis in a Spreadsheet

Fathom AI: Bot-Free Transcription & Smart Summaries

Calendly Review: Professional Scheduling Automation

Haiper AI Review: Cinematic Videos from Text Prompts

Tabnine Review: Private & Powerful AI for Developers

Integrately Review: One-Click Automations That Actually Work

Wrike Review: The Enterprise Work Platform for Humans + AI

Creator Camp: The A24 for Internet Creators

Avoma Review: AI Meeting Assistant + Conversation Intelligence

Prometheus: Jeff Bezos’ AI for the Physical World

Design: AI Design Platform for Logos, Brands & Websites

Framer: The Most Powerful No-Code Website Builder.

Julius AI: Your AI Data Analyst That Understands Spreadsheets.

Visme Review: Create Stunning Infographics & Presentations

Canva Review: Design Anything Beautiful in Minutes

Motion Review: AI That Plans Your Day and Manages Your Work

Physical Intelligence (π): General-Purpose AI for Robots

Figma Review: Where Design Teams Build Real Products

Levity Review: Reliable AI That Handles Your Freight Emails

Krisp: Best AI Noise Cancellation & Meeting Assistant.

CustomGPT Review: Your Own Private GPT Trained on Your Data.

Text Blaze Review: The Best Text Expander & Automation Tool.

Expertise AI Review: The Smartest AI for Website Conversions
Chatbase Review: The Easiest Way to Create Custom AI Agents

Zapier Review: The Best No-Code Automation Platform

Personal AI: Your Private Second Brain and AI Twin

ChatPDF Review: The Easiest Way to Understand Documents

Otter AI Review: Real-Time Transcription & Smart Meeting Intelligence

SingularityNET: The Decentralized AI Marketplace Powering Beneficial AGI

Whop Review: Own Your Audience and Monetize Your Ideas

Jenni AI Review: Write Papers with Traceable Citations & AI Power

Paragraph Review: Own Your Audience and Ideas.

SciSpace Review: Chat with 280M Papers & Write with Citations

Lately AI Review: The Smartest AI Content Repurposing Platform

Grammarly Review: Write Better, Faster, and More Professionally

AdCreative AI Review: Generate Winning Ads, Videos & Photoshoots in Seconds

Notion Review: The Ultimate All-in-One AI Workspace

Writesonic Review: Dominate Google + AI Search with One Platform

Glif Review: The Creative Agent Platform That Builds Full Campaigns
Cometly Review: The Best Marketing Attribution Platform for B2B

Arvow Review: AI That Writes, Optimizes, Publishes & Ranks for You

Rocket Review: Think. Build. Track. All in One AI System

CodeRabbit Review: AI That Makes Code Reviews Actually Enjoyable

Kilo Review: 500+ Models, Full Control, Zero Lock-In

Kin AI Review: The Privacy-First Personal AI Companion

Freebeat AI Review: The Best AI Music Video Generator with Real Beat Sync

Notis Review: Voice-First AI Assistant That Actually Gets Work Done

Black Forest Labs: FLUX 2 – The King of AI Image Generation

Elastic Review: Elasticsearch as the Ultimate Vector Database for AI

Liquid AI Review: The Future of Edge-Native AI Beyond Transformers
Komos AI Review: Turn Screen Recordings Into Compliant Workflows

Tonic Review: Safe, Realistic Test Data for Developers & AI Teams

Floot Review: Turn Ideas Into Working Websites & Apps in Minutes.

Micro1: Turning Human Brilliance into Scalable AI Training Data

Odyssey: Pioneering General-Purpose World Models Beyond Language AI

Bexorg Review: The AI + Whole-Human Brain Platform Revolutionizing Drug Discovery

Pangram: The Most Accurate AI Content Detector Trusted by Universities & Enterprises

Hightouch: The Composable CDP & Agentic Marketing Platform Enterprises Trust

Overlap AI Review: Turn Long Videos into Scalable Social Clips Automatically

Clouted Review: Turn Raw Footage into Millions of Views with Creator Networks
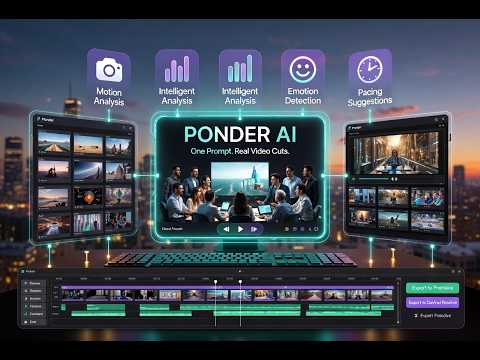
Ponder AI: Turn Raw Footage into Pro Rough Cuts with One Prompt

Enhanced: Science-Driven Performance & The Future of Human Competition

Joi AI Review: The Boldest & Most Entertaining AI Character Chat Platform

PapersWithCode Review: Trending AI Papers with Working Code.

Poolside Review: The Secure AI Platform Built for Real Enterprise Development

Viggle Review: The Best AI Character Animation & Motion Transfer Tool

Genesis AI Review: The Full-Stack Robotics Company Closing the Sim-to-Real Gap

BACH Review: Professional Multi-Shot AI Video for Real Filmmakers

AllenAI Review: The Non-Profit Powerhouse Building Open Superintelligence

Zyphra Review: The Efficient MoE Models Trained on AMD That Punch Above Their Weight

Klap Review: The AI Video Repurposing Tool Every Creator Needs

PlayCanvas Review: Build & Ship Browser 3D Experiences in Minutes

Humwork Review: When AI Agents Get Stuck, Humans Step In

Hyper3D Rodin Review: The Fastest Controllable 3D AI Generator

Magic Patterns Review: The AI Prototype Generator Product Teams Love

Linear Review: The AI-Era Issue Tracker That Teams Actually Love

PostHog Review: Product Analytics + Session Replay + Feature Flags in One Platform

Wispr Flow Review: The AI Voice Dictation That Actually Works Everywhere

Granola Review: Bot-Free AI Notes for Back-to-Back Meetings

Intercom: Where AI Agents and Human Teams Work Together Perfectly

Supabase: The Open-Source Firebase Alternative You’ll Actually Love

Gumloop Review: Build Production AI Agents Without Writing Code

Ineffable.ai Review: David Silver’s Bold Path to AGI Without Human Data

Andon Labs Review: The Real-World AI Takeover Experiment

Vault Review: Generate Full Songs & Stems with AI

Submagic Review: The Best AI Tool for Scroll-Stopping Captions.

TopView Review: The Best AI Video Maker for Marketers & E-commerce

InVideo AI Review: The Best AI Video Generator for Creators

DeviantArt Review: The World’s Largest Online Art Community

Conductor Review: Build Reliable Multi-Agent Workflows

Juicebox Review: Turn Ideas into Action with Intelligent AI

Mirage Review: From Text to Cinematic Videos in Minutes

Quasa Rewards Review: Get Rewarded for Discovering Great Tools

The Influencer Marketing Factory Review: Smart Discovery & Campaign Management

Beacons AI Review: Build Beautiful Creator Websites with AI.

Phota Labs Review: Ultra-Realistic Upscaling & Photo Restoration

Vercel Review: Instant Deployments & Global Edge Performance

Unsloth Review: The Fastest Way to Fine-Tune Open-Source Models

Vibecode Review: The Best AI App Builder for Everyone

Okara Review: The All-in-One AI Marketing Team for Founders

D-ID Review: The Leader in Digital Humans and Conversational Video

Ollama Review: The Best Open-Source Local AI Platform

Code Maestro Review: Project-Aware AI for Unity & Playable Ads

Percepta Review: The Serious Partner for Enterprise AI Adoption

Moonlake AI Review: The Future of AI-Powered World Modeling.

Quiver AI Review: Production-Ready Vectors from Text and Images

Flora Review: Node-Based Creative Environment with 50+ AI Models

Replicate Review: The Easiest Way to Deploy and Scale ML Models

Entire Review: Never Lose the Story Behind Your AI-Generated Code

LM Studio Review: The Best Desktop App for Local AI

LM Arena: The Most Trusted AI Model Battle Platform.

Bye Bye Paywall: Instantly Unlock Any Article Without Paying.

Gladia: The Most Accurate AI Audio Intelligence Platform.

Meshy AI: Text-to-3D & Image-to-3D at Lightning Speed.

Lemme: AI Live Video That Feels Completely Real.

Spikes Studio: AI That Turns Long Videos into Viral Clips Instantly.

Revid AI: The All-in-One AI Video Generator for Viral Shorts.

Topaz Labs: The Best AI Image & Video Enhancement Software.

Deepgram: The Most Accurate Real-Time Speech-to-Text Platform.

Retell AI: The Most Human-Like Voice AI Platform.

Groq: The Fastest AI Inference Platform on Earth.

OpenRouter: One API for Every AI Model — Smart Routing Done Right.

Spaitial AI: The Platform for Intelligent 3D Spatial Experiences.

Scribe: AI That Turns Any Process into Instant Step-by-Step Guides.

Kinetix: 3D-Conditioned AI Video with Real Motion Intelligence.

OpenAGI Lux: The Leading Computer-Use AI Model for Autonomous Agents.

Phygital+: The All-in-One AI Creative Workspace & Design Pipeline.

Character AI: The Ultimate Platform for Talking with AI Characters.

Limelight HQ: The All-in-One Creator Economy Operating System.

Chronicle: The AI-Powered Living Knowledge Platform for Teams.

Manus AI: Hands On AI That Turns Thoughts into Real Actions.

Brilliant Labs Halo: Open-Source AI Glasses for Curious Minds.

Palo: Personal AI for Pro Short-Form Creators.

Skild AI: The Omni-Bodied Brain Powering the Future of Physical AI.

AnswerThePublic: Visual Keyword Research & Content Ideas Tool by Neil Patel.

Hyper Island: The Creative Business School That Prepares You for the Unknown.

Planet Labs: Daily Global Satellite Imagery & Earth Intelligence Leader.

AppSumo: The Best Lifetime Deals Marketplace for Smart Entrepreneurs.

Lore: The AI-Powered Home for Deep Fandom & Obsessive Lore.

TrustMRR: The Verified Startup Revenue Database & Marketplace.

Salad: The Distributed GPU Cloud Saving Up to 90% on AI Compute.

1X Neo: The Gentle Home Humanoid Robot That Actually Helps.

Volinga: Professional 3D Gaussian Splatting for Virtual Production & VFX.

Delphi: Create Your Digital Mind and Scale Your Expertise 24/7.

Rumble: The Free-Speech Video Platform Challenging YouTube.

Plotset: The AI-Powered Platform That Turns Data into Beautiful Stories.

Phot AI: The AI Creative Engine That Turns Products into Winning Ads & Listings.

Supergrow: The AI-Powered LinkedIn Content Platform That Captures Your Real Voice.

Alma: AI-Powered Immigration Platform for Top Talent & Growing Companies.

Serval: The AI-Native ITSM Platform with Autonomous Agent Workforce.

Cognition: The Company Behind Devin — The World’s First AI Software Engineer.

Crosby: The Agentic AI Law Firm That Reviews Contracts in Under 1 Hour.

Emergent: The World’s First Agentic Vibe-Coding Platform.

Imagine Art: The Complete AI Creative Suite for Images, Video & Voice.

🚨CRYPTO SECURITY IS DEAD.

Oboe: The World’s First AI-Powered Personalized Learning Platform.

Arcads AI: Create Winning Video Ads with 1,000+ Realistic AI Actors.

Vylit: The AI-Powered 18+ Creator Platform Built for Real Connections.

Pocket Watch: The Largest Kids & Family Creator Media Company.

Recraft AI: The Ultimate AI Design Platform for Professional Vectors & Visuals.

Jasper: The AI Agent Workspace for Modern Marketing Teams.

Copy AI: The World’s First GTM AI Platform Review.

Reve Image: Reimagine Reality with AI-Powered Image Creation & Editing.

Mozart AI: The AI-Powered DAW That 10x Your Music Creation.

World Labs: The Leader in Spatial Intelligence & Large World Models.

Inception Point AI: The AI Company Building Thousands of Podcast Personalities.

Stability AI: The Leading Open Generative AI Platform.

Sakana AI: Nature-Inspired AI That’s Changing Everything.

K2 Think: The Most Efficient High-Performance AI Reasoning Model.

Tripo AI: The Fastest Text-to-3D & Image-to-3D Generator.

KIRI Engine: The Best Mobile 3D Scanner for Creators.

Greenbot Rizz AI: The Best Free AI Flirting Assistant.

AlterEgo: The Revolutionary Silent Speech Neural Interface.

Are You Paying for Content? Why Web3 is the Future of Earning | Quasa Insights

Creatable: The Best AI-Powered Creator Marketing Platform for eCommerce.

Crowdcast: The Best Platform for Interactive Live Events & Webinars.

CreatorsJet: The Best Automated Media Kit Platform for Creators.

Fourthwall: The Best Creator Commerce & Fan Monetization Platform.

Locals: The Best Creator-Owned Community Platform.

Opus Clip 2026: The Best AI Video Clip Generator for Viral Shorts.

Cartesia: The Fastest Real-Time Voice AI Platform.

Figure: The Leading Humanoid Robotics Company.

ComfyUI: The Most Powerful Node-Based AI Generation Tool.

Vivaldi: The Most Customizable Privacy-First Browser.

FilmSpark AI: The Best Story-First AI Video Production Platform.

Sync: The Best AI Lip-Sync & Visual Dubbing Platform.

Soul Machines: The Most Emotionally Intelligent AI Avatars.

Synthesia: The Best AI Video Generator with Realistic Avatars.

fal ai: The Fastest Generative AI Inference Platform.

Moises: The Best AI Music Platform for Musicians & Producers.

NAS IO: The Ultimate AI Co-Founder for Solopreneurs.

Movement: The Modern Community Platform for Creators.

Streamforge: The Smartest Influencer Discovery & Analytics Platform.

Higher Logic: The Leading Enterprise Community Platform for Associations.

Hivebrite: The Best All-in-One Community Platform for Organizations.

BuddyBoss: The Most Powerful All-in-One Community Platform for WordPress.

Mighty Networks: The Best All-in-One Community Platform.

Bettermode: The Best No-Code Customer Community Platform.

Circle: The Most Beautiful All-in-One Community Platform.

Hotmart: The Leading Platform for Selling Digital Products

July: The Ultimate Operating System for Creator Agencies.

Pensight: The Best All-in-One Platform for Creators.

Fanvue: The Leading AI-Powered Creator Monetization Platform.

Rokfin: The Best Subscription Platform for Independent Creators.

Heepsy: The Most Accurate Influencer Search & Analytics Platform.

CreatorIQ Review: Powerful Influencer Discovery & Campaign Management.

Mastodon: The Best Decentralized Alternative to Twitter & Instagram.

Nexo Review: Earn High Yields, Borrow & Spend Your Crypto.

Gamee: The Most Fun Casual Gaming Platform with Real Rewards.

Hang Review: Finally, a Beautiful and Organized Way to Group Chat.

Upkeep: The Easiest Way to Book Premium MedSpa Treatments.

MoldCo Review: The Patented 3-Step Protocol That Actually Works

Bright Harbor Review: Expert Help to Rebuild Faster After Any Disaster

State Affairs Review: Nonpartisan Coverage of All 50 State Legislatures

Outtake Review: Turn Long Videos into Viral Shorts in Minutes

Praktika AI Review: Speak New Languages with Lifelike AI Tutors.

Browse AI Review: The Most Powerful AI Web Scraper for Everyone

Shotgun Review: Discover & Buy Tickets to the Hottest Live Music Events

Bird Buddy Review: Best Smart Bird Feeder with Camera & AI Identification

Lottie Review: Compare Care Homes, Home Care & Retirement Options with Confidence

Bounce Review: The Smartest Way to Ditch Your Luggage and Enjoy Every Trip

Tapstitch Review: The High-Quality POD Platform for Serious Creators & Brands

Euka AI Review: Turn TikTok Creators Into Your Revenue Engine

Memories Review: AI That Finally Sees and Remembers Like Humans

Creatify: The AI Video Ad Generator Brands Use to Replace Entire Creative Teams

Jobright: Your Personal AI Career Co-Pilot That Lands You Better Jobs.

Pockla: The AI That Turns Brands into Top Creators at Scale.

Howbout: The Private Calendar That Turns “We Should Hang Out” Into “See You There”

Fanbasis Review: Sell Courses, Memberships & Digital Products in One Place.

GlobalComix 2026: The Ultimate All-in-One Digital Comics Platform.

Mile: The Members-Only Luxury Club That Saves You 60-90% on Designer Fashion.

Customuse Review: Create Roblox Assets in 30 Seconds: Customuse AI Full Guide.

Ceartas: The AI “Internet Delete Button” That Protects Creators Instantly.

Upside VC Review: Rising Star VC Firm Supporting Ambitious Founders.

Runna: Personalized AI Coaching for Runners of All Levels.

Menlo Ventures: The Founder-Centric VC Firm Backing Generational Technology Companies.

FirstMark Review: The Founder-First VC Backing Category-Defining Companies

Slow Ventures Creator Fund: Turning Creators into Unicorns.

Zencall: AI Phone Agents That Answer Calls & Book Appointments 24/7.

Krea Review: The All-in-One Creative AI Suite with 64+ Frontier Models.

Picsart: The All-in-One AI Creative Suite for 150 Million Creators.

Bolt: Prompt-to-Product AI That Builds Full Apps in Minutes.

Fyxer AI: Your Personal AI That Drafts Emails Exactly Like You.

11x Review: Autonomous Sales Automation That Actually Delivers Human Results.

Robin AI: The Legal Co-Pilot That Cuts Contract Review Time by 80%.

Decagon Review: AI Agents Turning CX into True Concierge Experiences

Hebbia: The Matrix-Powered AI Revolutionizing Investment Banking & PE.

Quasa Rewards: Earn QUA Tokens While Discovering AI & Web3 Projects.

Claude Opus 4.8: The New Standard in Autonomous Programming and AI Reliability

Nabla: AI That Lets Doctors Be Doctors Again.

Sana: The No-Code AI Agent Platform for Enterprise Knowledge & Automation.

Sixteenth: The 360° Creator Talent Management Platform.

Sierra: Enterprise AI Agents That Actually Work Like Real Employees.

Influential: AI That Makes Influencer Marketing Actually Work.

Relay: AI-Powered Automation That Works for You.

Leonardo AI: Next-Level AI Art & Video Generation.

Geneo: The Ultimate Generative Engine Optimization Platform.

Koah: Monetize AI Conversations Without Annoying Users.

DiaBrowser: The Intelligent AI-Native Browser That Actually Works With You.

Profound: The No-Code Platform for Building Real AI Employees.

Zora: The Decentralized Protocol That Gives Creators True Ownership.

Farcaster: The Real Decentralized Social Network.

Midjourney: Still the Gold Standard for AI Image Generation.

MathGPT Pro: The Ultimate AI Math Tutor and Step-by-Step Solver.

Strawberry Review: The Agentic AI Browser Every Professional Needs.

Anthropic: Safe, Smart, and Enterprise-Ready AI.

Pixverse: Turn Any Text or Image into Cinematic Videos in Seconds.

ElevenLabs: The Most Realistic AI Voice Platform – Full Review.

ZAI: The Next-Gen Generative AI Search Engine for Instant, Citied, and Actionable Answers.

Runway: The Generative AI Powerhouse Redefining Professional Video & Visual Effects.

Wondera: The AI-Driven Personal Studio Redefining Music Creation

Morphic: Finally, Search That Actually Understands What You Nee.

Qwen: The Best Open-Source Model You Can Actually Use at Scale

Neo: Lifelong Memory & Proactive AI Assistant That Runs Your Life.

Zendesk AI: Autonomous AI Agents Resolving 80%+ of Tickets – Full Review.

Menlo: Building the AI Brains for the Humanoid Robot Era – Full Review.

Perfect Corp: AI + AR Beauty Revolution – Virtual Try-On & Smart Recommendations.

Harvey: The Leading AI Legal Co-Pilot Transforming Law Firms – Full Review.

Clay: Turn Raw Leads into High-Converting Campaigns with Zero Manual Work – Guide.

Crescendo: Ultra-Realistic Emotional Voice Agents for Enterprises – Overview.

Replit: Cloud IDE Revolution – Build & Ship Apps in Minutes – Full Review.

Codingame: Turn Learning & Hiring into Addictive Coding Games – Overview.

Cursor: Ship Code 2–5× Faster with Cursor's Intelligent Editing – Insights.

Mercor: AI-Powered Talent Revolution – Hiring 80% Faster – Full Review.

Luma AI: Scale Visual Content Creation with AI Magic – Insights.

n8n: Open-Source AI Workflow Automation Revolution – Comprehensive Review.

Leena AI: The Intelligent HR/IT/Finance Concierge for Global Teams – Overview.

Flowise: Open-Source Visual Low-Code Platform for AI Agents & RAG – Comprehensive Review.

Thingiverse: World's Largest Free 3D Model Library – Overview.

Lara Translate: Instant, Context-Aware Translation for Global Brands – Overview.

Udio: Ultra-Realistic Songs from Text Prompts – Overview.

Lovart: Automate Full Campaigns from Logo to Video – Overview.

Proton: End-to-End Encrypted Suite for Secure Digital Life – Overview.

Passes: Own Your Audience with 90% Take-Home & Anti-Leak Tech – Overview.

Fansly: The Ultimate Creator-First Platform – Comprehensive Review.

Pika: Instant Expressive AI Videos for Creators & Marketers – Guide.

Creator Science: Experiment Your Way to Sustainable Creator Success – 2026 Overview.

Composite: AI-Powered Autopilot for Any Website in 2026 – Expert Guide.

Xona: The Ultimate AI Tool for Virtual Staging & More – Guide.

Promptessor: Score & Refine Prompts for 50% Better AI Outputs – Overview.

Star Method Coach: Master Behavioral Interviews with AI – Full Review.

Adkit: AI-Powered Ad Creation & Spy Tool Revolution – Full Review

Vizcom: Instant Sketch-to-3D Rendering for Creatives

DataSquirrel: Revolutionizing AI-Driven Data Analysis for Non-Tech Pros . Comprehensive Review.

ChatHelp: Transforming Workflows with AI Tools – Comprehensive Review

eesel ai: Revolutionizing CX with AI Agents – Comprehensive Review

Twig: Revolutionizing B2B Customer Support with AI-Driven RAG Automation

DigitalGenius: Revolutionizing Autonomous Customer Service with AI

Voila AI: Revolutionizing AI Productivity with Multi-Modal Magic

FastWrite: Lightning-Fast AI Writing Assistant

QuickCreator: Revolutionizing Agentic AI Marketing for SMBs

Easy-Peasy AI: Revolutionizing Effortless AI Writing & Content Creation

Lightfield: Revolutionizing AI-Native CRM for Startups & Teams

Prismix AI: Revolutionizing Social Media Automation with AI

Poe: Revolutionizing Multi-AI Chat with Custom Bots & Collaboration

Teal: Revolutionizing Job Searching with AI-Powered Career Growth

Napkin AI: Revolutionizing Visual Storytelling from Text with AI

Ideogram: Redefining AI Image Generation with Precise Text Rendering

Gamma: Revolutionizing AI-Powered Presentations & Content Creation

Quasa.io: Pioneering Web3 Freelance with AI Matching & Crypto Empowerment
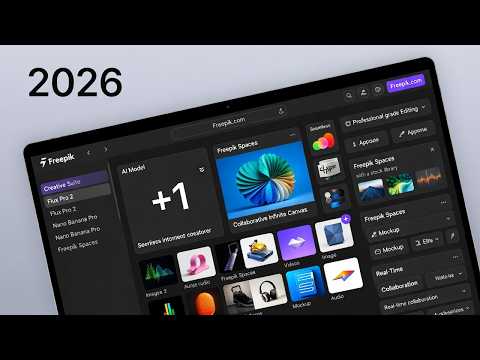
Freepik: Revolutionizing AI-Driven Content Creation for Designers & Teams

Pump Fun: Revolutionizing Meme Coin Launches on Solana with Instant, Fair Fun in 2026

Chat4Data: Revolutionizing Web Data Extraction with Conversational AI

Clever CSV: Revolutionizing Bulk Content from Spreadsheets with AI

Martin: Your Proactive AI Personal Assistant – The Modern "Jarvis" for Busy Professionals

Koala AI – All-in-One SEO Writer: Generate Publish-Ready Long-Form Content from Keywords in Minutes

SymphonyAI: Building AI Intelligence for Enterprises – Rivaling Palantir in Customization & Results

BizPlanner AI: "Investor-Ready in 15 Minutes" – AI Efficiency for Global Business Builders

PrometAI: Essential AI for Business Planning – From Structure to Projections in Seconds

Top 3 Web3 Tools for Creators 2026

FoxyApps: The Fastest Way to Launch Native Apps – Unlimited Previews, Real Devices

VenturusAI – Instant Reports for Startup Ideas: Validate, Plan & Pitch with Ease

Stratup AI – Discover 100,000+ Business Concepts & Validate Ideas in Seconds

Informly: The Must-Have AI Ally for Entrepreneurs – Depth, Accuracy & Free Basics

BlackInk AI: AI-Driven Creativity for Tattoos – Privacy, Customization & Artist-Ready Outputs

X-Doc AI – Unmatched Accuracy for High-Volume Docs & Audio: 99% Precision, Zero Compromise

Storiaverse: A Fresh Evolution in Storytelling – Switch Between Text & Animation Seamlessly

Immutable – Your Hub for Web3 Gaming: Scalable NFTs, Player Ownership & Developer Tools

OpenClaw (formerly Clawdbot/Moltbot): Innovative Open-Source AI Assistant Redefining Productivity

The Sandbox: Rivaling Roblox with NFT Ownership, User-Generated Games & Creator Economy

Lovable: AI-Powered App Builder – Turn Ideas into Full Web Apps in Minutes

Reclaim – Intelligent Scheduling with AI: Reclaim Hours, Reduce Burnout & Boost Productivity

Thea – Personalized AI Tools for Smarter Studying: Quizzes, Summaries & Games Made Easy

MakeInfluencer: Deploy Custom AI Stars with Veo & Lip Sync – Revolutionize Marketing & Content

Imagine Explainers – Revolutionary No-Code Platform for Animated Explainers & Visual Storytelling

Make: The Visual Powerhouse for AI-Driven Automations – Boost Efficiency Without Coding

Cameo: The Iconic Platform for Personalized Celebrity Videos & Creator Shoutouts

Spring: Empower Creators to Sell Custom Merch & Digital Products with Zero Upfront Costs

Pinata: The Go-To IPFS Pinning Service for Web3 – Affordable, Flexible & Developer-Friendly

Sprout Social: "All Business is Social" – Cutting-Edge Management for Multi-Network Success

The State of Hybrid Freelance 2026: The QUASA Report (Update)

Dream Recorder – Revolutionary DIY AI Device for Capturing & Visualizing Your Subconscious

MiniMax – Affordable LLM Powerhouse Rivaling OpenAI in Efficiency & Accessibility

Higgsfield on Quasa.io: Revolutionizing AI-Driven Video Creation with Hollywood-Level Realism

Revolutionizing Voice AI: Inworld TTS on Quasa.io – A Game-Changer for Low-Latency, Multilingual TTS

HeyGen – Create Pro Talking-Head Videos with Ultra-Realistic Avatars & Lip-Sync in Minutes

Buildots: 360° AI Vision That Tracks Every Task Against BIM & Schedule – No More Surprises

Speechify: Hands-Free Reading Assistant – Dyslexia-Friendly & Super Fast

Scholarcy – Instant Summary Cards, Flashcards & Critical Insights Without Reading Everything

Ryne AI: From Custom Portraits to Emotional Conversations – Feels Shockingly Real

Gumroad: The Simplest Way to Sell Digital Products & Build Your Creator Business

Datawrapper: The Fastest Way to Create Beautiful, Interactive Charts & Maps

EntriesAI: The Thoughtful AI Journal That Turns Your Thoughts into Deep Insights

Aura – The Caring AI Coach That Feels Like a Kind Friend for Self-Compassion & Calm

Cliply: Turn Any Long Video into 50 Viral Shorts – AI Magic in Minutes

Top 10 Web3 Tools for Creators: AI, NFTs, & Crypto Earnings Game-Changers!

FemFounder – Sisterhood, Masterclasses & Tools for Female Entrepreneurs to Thrive

Beehiiv vs Substack vs Mirror 2026: Lowest Fees Revealed (Keep 97% of Your Earnings!)

Self-Love Rainbow: The Beautiful 30-Day Journey to Radical Self-Acceptance in 2026

Board Game Arena: The Ultimate Free Online Hub for 300+ Board Games

Anara: The Elegant Digital Storefront for Creators Monetizing in 2026

Later: Reliable Scheduling, Grid Previews & Smart Posting for Creators & Brands

Impact – All-in-One Partnership Management: Affiliates, Influencers & Referrals with Real ROI

Grin – Performance Influencer Marketing: Gifting, Affiliates, Tracking & Fast Payouts

ShopMy – The Slickest Way to Monetize Your “What I’m Loving” Content

Ensemble: The Elegant Real-Time Workspace for Collaborative Creator Content

beehiiv – Build, Monetize & Grow Newsletters Without 10% Forever Fees

OTH Network: The Web3 Alternative Giving Creators Full Control & Upside

Jellysmack: Turn One Long Video into 50 Viral Shorts – AI + Editors in Minutes

Uscreen: The Creator’s Choice for Direct Revenue & Branded Video Experiences

Merit Beauty – Skin-First Luxury: Effortless Radiance, No Heavy Makeup

Shine Talent Group – Hands-On Management for Top Creators & Long-Term Growth

Spotter: The Affordable Tool for Catching Every Brand Mention & Trend

Locked In: AI Coach, Streaks, Penalties & Leaderboards – Deep Work on Steroids

MobyGratis: Cinematic, Unreleased Moby Music – Completely Free for Non-Commercial Use
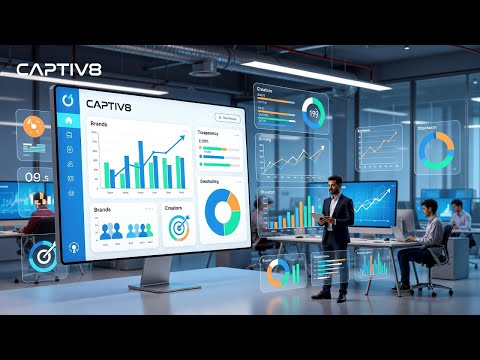
Captiv8: AI-Powered Influencer Marketing with Fast Payments & Real Analytics

Hummingbird-0: Zero-Shot Lip-Sync AI That Looks Almost Too Real

Own: The Privacy-First Social Platform Where You Truly Own Your Audience

Space Selfie – Your Selfie on the Moon, Mars or ISS in Seconds

Quasa Connect: The World's First Web3 Freelance Platform – Earn in Crypto, No Borders!

Kortix: Build Smart AI Agents & Automations – No Code, Just Results

Tutor AI: Your 24/7 Personal AI Tutor That Builds Custom Courses in Seconds

Mr. Donald Save Vatican – Hilarious Indie Game Where Trump Fights Aliens & Biden Mechs

Decentraland: True Ownership in a Decentralized Metaverse – Still a Web3 Cornerstone

Resemble AI: Clone Any Voice & Create Ultra-Realistic Speech in Seconds

Supercut: Turn Hours of Footage into Viral Shorts in Seconds with AI

Hedra: AI That Turns Text & Images into Lifelike Talking, Singing Avatars in Seconds

Kajabi: Professional, Scalable & Creator-First – The Complete Online Business Tool

Interviewsby: Free AI That Prepares You to Crush Any Job Interview

BuzzFeed: Millions of Quizzes Daily, Endless Shares – Still Unstoppable

Flourish: Turn Any Spreadsheet into Stunning Interactive Visuals – No Code Needed

Retrograde: The AI Talent Agent That Cuts Creator Commissions in Half

PageOn AI: Create Stunning Presentations & Interactive Content in Minutes with AI

Subs: The New Creator Subscription Platform from OnlyFans' Founder

BuildCores: Build Your Dream PC in 3D – No More Guesswork

Stardew Valley 1.7: The Cozy Farming Sim Update Dropping This Month

Nucleus Genomics: Unlock 100% of Your DNA – The Future of Personalized Health

Cluely: The Invisible AI That Sparks Outrage and Raises Millions

Skywork: Analyze 100 NASDAQ Stocks in Minutes – The AI Investors Dream About in 2026

Nick DiGiovanni: From MasterChef to 50M+ Followers – The King of Chaotic Cooking

Genspark: The Super Agent That Does Your Work While You Relax

Coach Courteney’s 3-2-1 Magic: Strength + Pilates + Real Results

Create Hollywood-Level Videos in Minutes – LTX Studio Is Here

LOVO AI: Future of Voice

LockedIn AI Your Secret Weapon

Influencer

Flux Kontext

Whalar Creator Powerhouse

Favikon B2B Marketing, Solved

Artisan AI: Future of Sales

Explaining Popularity Bazaar

POPFLEX: Hacking Activewear

Small Bets: For Creators

Streamer University Review

The Explainer: Archive.com

Laylo Own Your Audience

QUASA — Leading Web3 Freelance, AI & Crypto Ecosystem

Stan Store Review

Mistral AI 2026: Europe’s Most Powerful Open AI Platform
Krea Review: The All-in-One Creative AI Suite with 64+ Frontier Models
ComfyUI 2026: The Most Powerful Node-Based AI Generation Tool
Mozart AI 2026: The AI-Powered DAW That 10x Your Music Creation

Kling AI – Hyper-Realistic Motion & Physics That Beats Runway & Luma Right Now
