Что такое кластерный анализ? Полное руководство для начинающих
Добрый день друзья!
При анализе больших групп данных вы, скорее всего, будете ошеломлены количеством информации, которую они содержат.
В таких случаях рекомендуется разделять элементы данных по признаку их сходства, чтобы упростить работу.
Слышали ли вы когда-нибудь о кластерном анализе?
Для многих специалистов в области обработки данных он является одним из основных способов выявления дискретных групп в данных, однако многие начинающие специалисты остаются в неведении относительно того, что такое кластерный анализ и как он работает.
В этой статье мы познакомим вас с концепцией кластерного анализа, его преимуществами, распространенными алгоритмами, способами их оценки, а также с некоторыми реальными приложениями.
1. Кластерный анализ: Что это такое и как он работает
Чтобы лучше понять суть кластерного анализа, давайте сначала разберемся, что это такое.
Что такое кластерный анализ?

Кластерный анализ можно рассматривать как поиск естественных группировок в данных.
Как работает кластерный анализ?
Кластерный анализ предполагает анализ набора данных и группировку схожих наблюдений в отдельные кластеры, что позволяет выявить закономерности и взаимосвязи в данных.
Кластерный анализ широко используется в аналитике данных в различных областях, таких как маркетинг, биология, социология, распознавание образов и моделей.
Кластерный анализ различается в зависимости от типа используемого алгоритма кластеризации.
2. Каковы преимущества кластерного анализа?
Концепция кластерного анализа звучит прекрасно, но каковы его реальные преимущества?
Вот их перечень:
Выявление групп и взаимосвязей

Это позволяет глубже понять структуру, лежащую в основе данных.
Вероятно, самым большим преимуществом использования кластерного анализа является способность находить сходства и различия в больших наборах данных, что позволяет выявить новые тенденции и возможности для дальнейших исследований.
Снижение сложности данных
Кластерный анализ может быть использован для снижения сложности больших наборов данных, что облегчает их анализ и интерпретацию.
Например, группируя похожие объекты, можно уменьшить количество измерений данных. Это может дать преимущества в виде более быстрого и упрощенного анализа.
Кластеризация также может помочь исключить нерелевантные данные, не имеющие сходства. В результате вы получите более оптимизированный процесс анализа.
Улучшение визуального представления
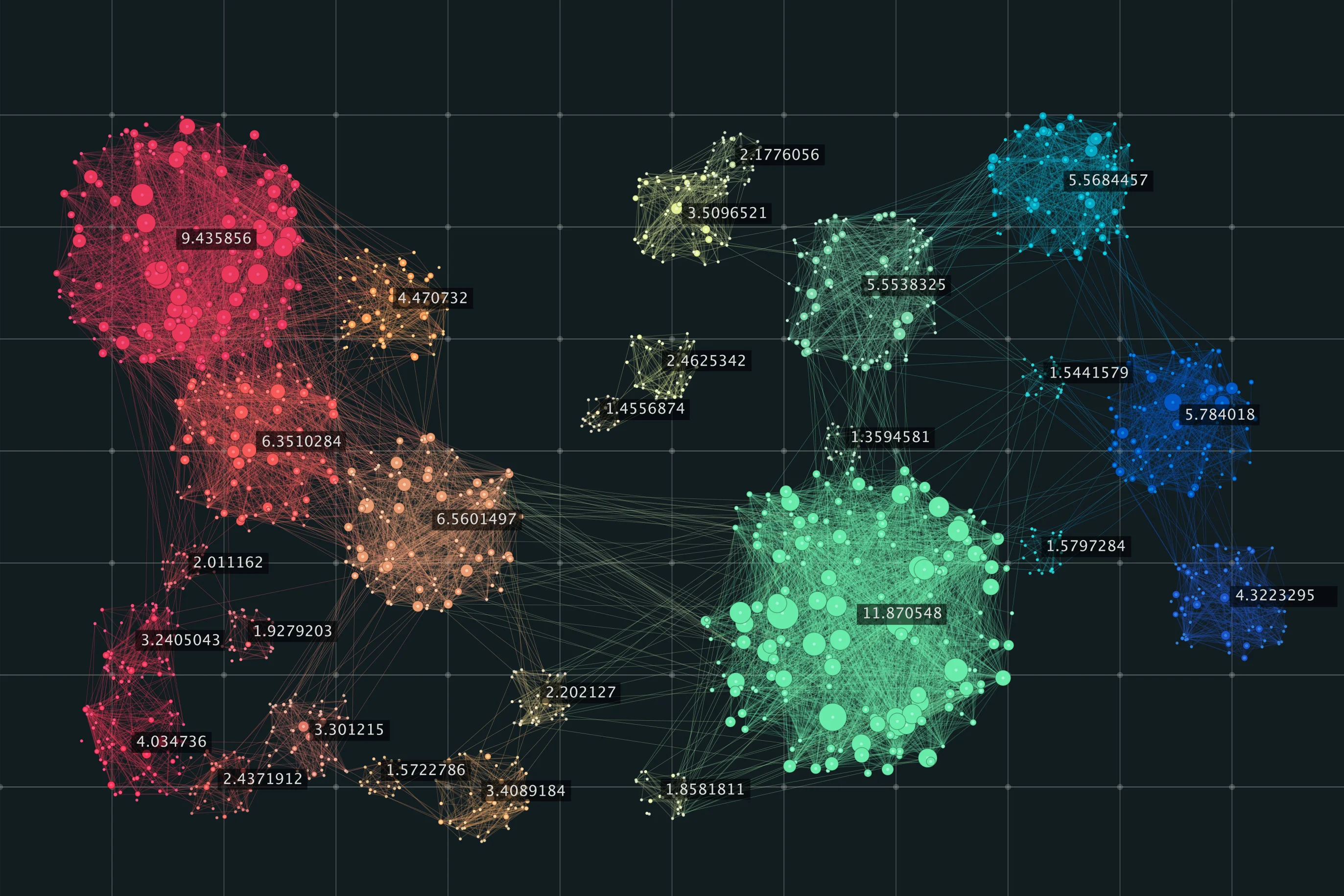
В результате кластерного анализа часто создаются визуализации данных о кластерах, такие как диаграммы рассеяния или дендрограммы.
Эти визуализации могут быть мощными инструментами для передачи сложной информации. Поскольку кластерные диаграммы просты для интерпретации и понимания, их можно включать в презентации.

Через год сможете начать работать Junior-аналитиком, параллельно продолжите проходить курс и дорастёте до уровня Middle.
3. Алгоритмы кластеризации: Какой из них использовать?
Как уже говорилось, приступая к кластерному анализу, необходимо выбрать один из подходящих алгоритмов кластеризации.
Существует достаточно много типов алгоритмов кластеризации, и каждый из них используется по-разному.
Ниже приведены пять наиболее распространенных типов алгоритмов кластеризации:
1. Кластеризация на основе центроида
Кластеризация на основе центроидов - это метод кластеризации, при котором набор данных разбивается на схожие группы на основе расстояния между их центроидами.

Алгоритм кластеризации k-means является одним из наиболее распространенных методов кластеризации на основе центроида.
В этом методе предполагается, что центр каждого кластера представляет каждый кластер.
Его цель - найти оптимальные k кластеров в заданном наборе данных путем итеративной минимизации суммарного расстояния между каждой точкой и назначенным ей центроидом кластера.
Другие методы кластеризации на основе центроида включают нечеткий метод c-means.
2. Кластеризация на основе связности
Кластеризация на основе связности, также известная как иерархическая кластеризация, объединяет точки данных на основе близости и связности их атрибутов.
Проще говоря, этот метод определяет кластеры на основе того, насколько близко точки данных находятся друг к другу. Идея заключается в том, что объекты, расположенные ближе, более тесно связаны между собой, чем объекты, расположенные далеко друг от друга.
Для реализации кластеризации на основе связности необходимо определить, какие точки данных будут использоваться, и измерить их сходство или несходство с помощью метрики расстояния.
После этого строится мера связности (например, граф или сеть) для установления взаимосвязей между точками данных.
Наконец, алгоритм кластеризации использует эту информацию о связности для группировки точек данных в кластеры, отражающие их базовое сходство.
Обычно это визуализируется в виде дендрограммы, которая выглядит как иерархическое дерево (отсюда и название!).
3. Кластеризация на основе распределения

В отличие от кластеризации на основе центроида, она использует статистические закономерности для выявления кластеров в данных.
В кластеризации на основе распределения часто используются следующие алгоритмы:
- Модель гауссовой смеси (GMM)
- Максимизация ожиданий (EM)
В модели гауссовой смеси (GMM) кластеры определяются путем поиска точек данных, имеющих схожее распределение.
Однако кластеризация, основанная на распределении, очень склонна к чрезмерной подгонке, когда кластеризация слишком сильно зависит от набора данных и не позволяет делать точные прогнозы.
4. Кластеризация на основе плотности

В отличие от других алгоритмов кластеризации, таких как K-means и иерархическая кластеризация, кластеризация на основе плотности позволяет обнаруживать кластеры любой формы, размера и плотности.
Кластеризация по плотности особенно полезна при работе с наборами данных, содержащими шумы или помехи, или когда у нас нет предварительных знаний о количестве кластеров в данных.
Вот некоторые из ее ключевых особенностей:
- Возможность обнаружения кластеров произвольной формы и размера
- Возможность работы с шумом и выбросами
- Не требует предварительного задания количества кластеров
- Может работать с нелинейными, непараметрическими наборами данных.
Ниже приведен список некоторых распространенных алгоритмов кластеризации на основе плотности:
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
- OPTICS (Ordering Points To Identify the Clustering Structure)
- HDBSCAN (Hierarchical Density-Based Spatial Clustering and Application with Noise)
5. Кластеризация на основе сетки
Кластеризация на основе сетки разбивает высокоразмерный набор данных на ячейки (разделяющиеся наборы непересекающихся подобластей).
Каждой ячейке присваивается уникальный идентификатор, называемый ID ячейки, и все точки данных, попадающие в ячейку, считаются принадлежащими одному кластеру.
Кластеризация на основе сетки является эффективным алгоритмом для анализа больших многомерных наборов данных, поскольку позволяет сократить время поиска ближайших соседей, что является обычным шагом во многих методах кластеризации.
4. Метрики оценки для кластерного анализа
Существует несколько оценочных метрик для кластерного анализа, и выбор подходящей метрики зависит от типа используемого алгоритма кластеризации и понимания данных.

- Внешние показатели
- Внутренние показатели
Ниже приведены некоторые распространенные метрики оценки для кластерного анализа:
1. Внешние показатели
Для оценки эффективности алгоритма кластеризации используются внешние данные или информация из внешней среды.
Истинные данные - это данные о метках, которые подтверждают класс или кластер, к которому принадлежит каждая точка данных.
Внешние меры можно использовать, когда мы знаем истинные метки и хотим оценить, насколько хорошо работает алгоритм кластеризации.
К распространенным внешним показателям относятся:
- F-измерение/F-score: Эта метрика определяет точность алгоритма кластеризации, рассматривая точность и отзыв.
- Чистота: Эта метрика измеряет долю точек данных, которые правильно отнесены к тому же классу или кластеру, к которому они принадлежат.
- Индекс Рэнда: Это мера сходства между истинными и предсказанными метками алгоритма кластеризации, варьирующаяся от 0 до 1. Более высокое значение указывает на более высокую эффективность кластеризации.
2. Внутренние показатели

Другими словами, они измеряют качество работы алгоритма кластеризации на основе взаимосвязей точек данных в наборе данных. Их можно использовать, когда у нас нет предварительных знаний или меток данных.
К общим внутренним показателям относятся:
- Силуэтная оценка: Эта метрика измеряет сходство и несходство каждой точки данных относительно ее собственного кластера и всех остальных кластеров.
- Индекс Дэвиса-Болдина: Эта метрика рассчитывает отношение внутрикластерного расстояния к межкластерному. Чем меньше значение индекса, тем выше эффективность кластеризации.
- Индекс Калинского-Харабаша: Также известный как критерий Variance Ratio, измеряет отношение межкластерной дисперсии к внутрикластерной дисперсии. Чем выше коэффициент Калинского-Харабаша, тем более определенным является кластер.
Эти оценочные метрики помогают сравнить производительность различных алгоритмов и моделей кластеризации, оптимизировать параметры кластеризации, а также проверить точность и качество результатов кластеризации.
Для обеспечения эффективности алгоритмов кластеризации и принятия надежных решений при кластерном анализе рекомендуется использовать несколько оценочных метрик.
5. Реальные применения кластерного анализа
Кластерный анализ - это мощный метод обучения без контроля, который широко используется для анализа данных в различных отраслях и сферах. Вот некоторые реальные примеры применения кластерного анализа:
1. Сегментация рынка
Компании используют кластерный анализ для сегментирования своей клиентской базы на различные группы.
При этом анализируются различные атрибуты клиентов, такие как:
- возраст
- пол
- покупательское поведение
- местоположение
Предприятия могут лучше понять свою клиентскую базу и разработать целевые маркетинговые стратегии для удовлетворения их потребностей.
2. Сегментация изображений в здравоохранении
Врачи используют методы кластеризации для сегментирования изображений пораженных тканей на различные группы на основе определенных биомаркеров, таких как размер, форма и цвет.
Эта техника позволяет врачам обнаруживать ранние признаки рака или других заболеваний.
3. Системы рекомендаций

При этом изучаются такие данные о поведении пользователей, как количество кликов, продолжительность просмотра определенного контента и количество повторов.
Эти данные можно объединить в кластеры, чтобы получить представление о предпочтениях пользователей и улучшить существующие рекомендации для них.
4. Анализ рисков в страховании
Страховые компании используют кластерный анализ для сегментации различных полисов и уровней риска клиентов.
Применяя методы кластеризации, страховая компания может более точно определить степень риска по своим страховым полисам и взымать страховые взносы в зависимости от потенциального риска.
5. Анализ социальных сетей
Приложения для социальных сетей могут собирать огромное количество данных от своих пользователей. Недавние дискуссии вокруг таких приложений, как TikTok или новый Twitter-подобный Threads компании Meta, являются хорошим напоминанием об этом.
Группируя и изучая социальные взаимодействия пользователей, можно сегментировать их по возрасту, демографическим характеристикам или покупательскому поведению, что приведет к появлению целевых объявлений и повысит общую эффективность размещения рекламы.
Итоги
Как видите, кластерный анализ является мощным методом обучения без контроля.
В заключение приведем несколько ключевых выводов:
- Он дает множество преимуществ при анализе данных, таких как оптимизация анализа и представление данных с помощью визуализации.
- Для достижения наилучших результатов алгоритмы кластеризации должны быть тщательно подобраны в соответствии с их типом.
- Для определения эффективности кластеризации необходимо оценивать внешние и внутренние показатели.
- Кластерный анализ может применяться в различных отраслях.
Спасибо за внимание и до новых встреч!
Подпишитесь на рассылку
Получайте свежие новости Web3, AI и криптовалют прямо на вашу почту.