Это не очередной академический тест. ALE — настоящий «выпускной экзамен» для ИИ-агентов. Более 1490 реальных долгосрочных задач из 55 отраслей экономики США (по классификации O*NET/SOC 2018). Задачи взяты напрямую из профессионального опыта реальных специалистов.
Агент должен работать в полноценных виртуальных машинах (Linux и Windows), используя тяжёлый профессиональный софт: Siemens NX, Unreal Engine, Adobe After Effects, FSLeyes и многие другие.
Бенчмарк оценивает пять функциональных слоёв:
Brain (рассуждения)
Eyes (визуальное восприятие)
Body (оркестрация)
Hands (использование инструментов)
Feet (исполнение в runtime)
Особенность ALE — жёсткие правила. Минимальное использование «LLM-as-a-judge» (всего 6,8%). Большинство задач оценивается детерминированно — сравнивается реальный результат агента с экспертным ground truth.
Результаты шокируют
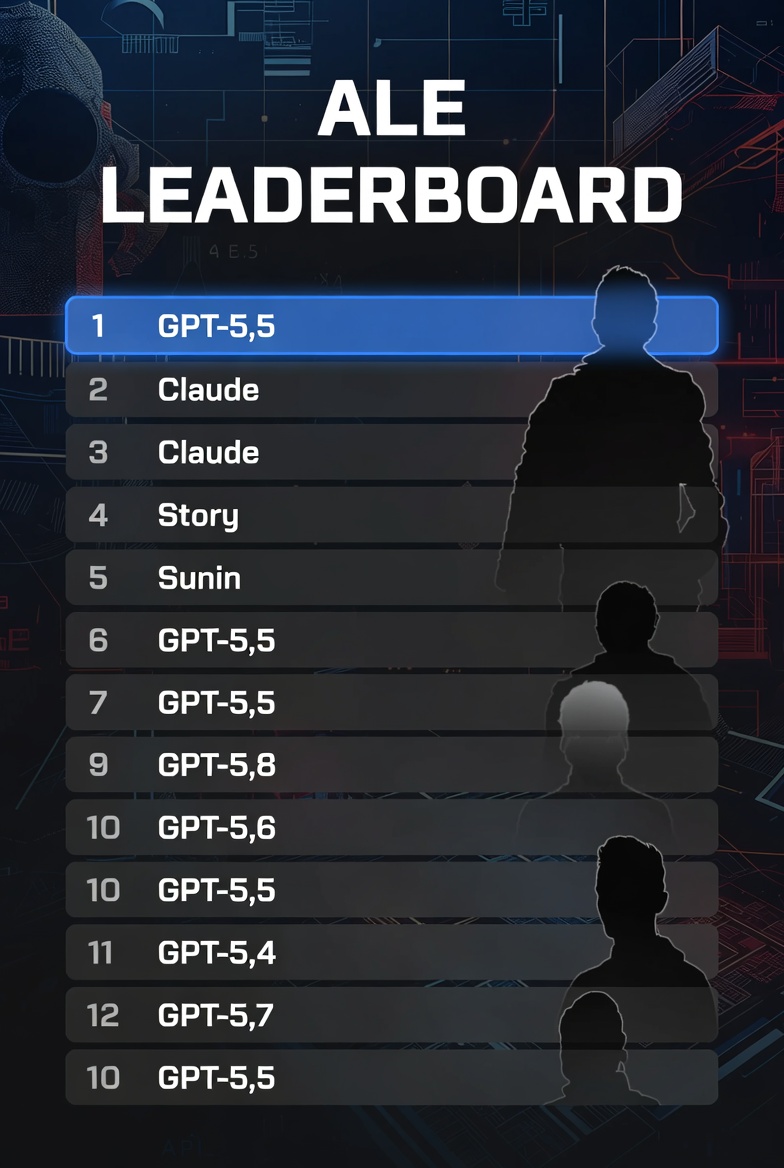
Топ-5 на ALE Leaderboard:
Codex harness (GPT-5.5) — 24,0% pass rate
Ale Claw (GPT-5.5) — 23,0%
Claude Code (Claude Fable 5) — 22,0%
OpenClaw (GPT-5.5) — 21,1%
Cursor CLI (Composer 2.5) — 20,4%
На самом сложном уровне Last-Exam многие модели, включая Claude Opus 4.8 и Gemini CLI, показали 0,0%.
Как ALE защищается от обмана
Авторы (более 300 экспертов из 100+ институтов) решили главные проблемы предыдущих бенчмарков:
Только 10% задач публичные.
Остальные 1300+ — закрытые и регулярно обновляются (rolling release).
Есть два зачёта: Full (с лицензионным ПО) и Unlicensed (только бесплатные инструменты).
Это позволяет избежать contamination и честно сравнивать модели.
вывод
Даже лидеры рынка — GPT-5.5 и новейший Claude Fable 5 — проходят всего около одной пятой реальных профессиональных задач. Это жёсткий, но честный reality check.
Zengyi Qin, MIT PhD researcher и один из авторов, написал:
Claude Opus 4.8 имеет 0.0% на самом сложном подмножестве. Рад был внести вклад в этот бенчмарк.
Пока компании вкладывают миллиарды в агентов, ALE напоминает: до настоящей замены высококвалифицированных специалистов ещё далеко. Но тот, кто первым научится стабильно проходить этот «выпускной экзамен», получит огромное преимущество на рынке труда.